I’m training for Vätternrundan, an annual one-day bike tour around Sweden’s Lake Vättern: 315 kilometers (about 200 miles) on the bike, ten to thirteen hours start to finish, the kind of event that punishes anyone who arrives undertrained or undernourished. I’m also 188 pounds trying to get to 170 without losing the power I’ve built. Those two goals pull in opposite directions in the obvious way, and the only way to navigate them is to match what I eat to what I’m training that day.
The complication with most nutrition apps is that calorie targets aren’t a single number; they’re a function of what you’re doing on the bike. A rest day and a four-hour endurance ride aren’t the same problem, and a 90-minute hard interval workout and a 90-minute easy endurance ride aren’t either. MyFitnessPal will happily let me eat 2,200 calories the day my plan calls for 4,300, and it has no opinion about whether that’s going to cost me the next day’s hard session.
So I built one that does.
What it actually is
A Python codebase, a Postgres database, a Discord bot, a few scheduled scripts, and several language models doing the parts no static formula can do. The infrastructure is the easy half. The hard half is what’s encoded inside it: a synthesized nutrition research base for endurance athletes in their 40s and beyond, four tightly-bounded prompts that pin each language model to a specific job, and a translation layer that turns what TrainingPeaks (the app I use to plan rides and record what I actually did) reports into the inputs those prompts need.
The visible pieces fit together like this:
- An auto-logged baseline breakfast at 7:30 AM, skipped on fast days or during travel.
- Discord check-ins at morning snack, lunch, and dinner that read whatever I type or photograph and turn it into calories, protein, carbs, fat, and fiber.
- A daily pull from TrainingPeaks that picks the right calorie and macro target from the planned training load, then updates the carb target to match measured ride calories the moment the ride lands.
- A dashboard with daily intake, deficit, weight, training load, and protein per meal on one page.
- A 9 PM daily summary that closes the day, and a Sunday weekly report that surfaces patterns I keep missing.
- A coaching response, on request, of one specific recommendation in two or three sentences, with bullets and moralizing banned by the prompt that runs it.
Underneath those bullets, the language models do most of the actual thinking. The food parser turns descriptions or photos into calories, protein, carbs, fat, fiber, and a confidence score; it sizes portions using a method that treats my hand as the scale reference; and it enforces the no-added-sugar and no-alcohol rules as hard limits. The photo estimator uses my hand as the primary scale reference, falls back to standard meal-prep containers and a regular dinner plate when the hand isn’t visible, and returns a short readout for each photo: which reference it used, what it estimated, and how confident it is. The check-in writer drafts the Discord meal-window messages so they vary in phrasing, stay under 200 characters, and never moralize. The advice model gets the day’s targets, the planned and completed workout, what’s logged so far, and a tight prompt that limits the answer to two or three sentences of specific, performance-relevant guidance grounded in the research base.
The research base took weeks to assemble before most of the code was written. A synthesized endurance-cycling nutrition guide of about 350 lines covers calorie and macro targets for each kind of training day, nutrient timing before, during, and after the ride, weight loss while maintaining power, matching carb intake to training intensity (and the limits of that strategy), hydration and sodium per condition, warning signs of chronic under-fueling, and a weekly template. Sources include the Gatorade Sports Science Institute on protein needs for older endurance athletes, multiple studies on under-fueling and its hormonal consequences, research summaries from 2021 through 2025 on matching carbs to training, USA Cycling’s sweat-rate methodology, and per-hour fueling guides for during the ride from Precision Hydration and Road Cycling Academy. The system prompts pull from that document, so when the bot tells me to eat 150g of carbs before bed it isn’t generic; it’s the application of a specific rule from a specific cited body of evidence to today’s specific situation.
The point of all of it is to make the system aware enough of what I rode and what an older endurance athlete’s body actually demands that I never have to translate “I just rode four hours easy” into “today I should eat 4,300 not 2,200, with 174g of protein split across four meals of 30g or more per serving (older muscle needs a bigger dose at each meal to actually rebuild), about 700g of carbs to refuel the muscles and replace what got burned, and the biggest carb hit landing inside the two hours after the ride.” The system does that translation on its own. I just answer the question of what I ate.
How food gets in
Three paths.
For things I eat every day, the system already knows. Mu Mu Muesli with berries and 2% milk is my pre-ride breakfast every single morning, so the scheduler auto-logs it at 7:30 with the calories and macros pre-resolved. During scheduled dairy-free windows, the same job swaps in almond milk and adjusts calories without me having to remember.
For everything else, I describe it in Discord. “Chopt shrimp spring roll salad.” “Thistle chicken bowl.” “Two eggs and a slice of sourdough.” A food parser turns the description into calories, protein, carbs, fat, fiber, and a confidence score. Cached items like Kind bars, Thistle meals, and Chopt entries come back deterministic. Restaurant meals come back as estimates with the confidence flagged so I know how much to trust the number. Foods with hidden added sugar get flagged regardless of whether I chose to eat them, because suppressing that flag would defeat the point of having a system in the first place.
For ambiguous portions, photos. I take a picture of the plate with my hand in frame, send it to the bot, and the portion-sizing method does the rest.
The hand reference
This is the piece I’m most pleased with. The portion-sizing method uses my hand as the primary scale reference, and it’s surprisingly accurate once you commit to it.
| Reference | Estimate |
|---|---|
| Palm without fingers | 3-4 oz of protein (chicken, fish, meat) |
| Full hand span | 6-8 oz depending on thickness |
| Fist size | ~1 cup volume (rice, vegetables) |
| Cupped hand | ~½ cup (nuts, grains) |
| Thumb tip to first knuckle | ~1 tablespoon (sauces, dressings, butter) |
When the hand isn’t visible, the model falls back to standard meal-prep containers and a 10 to 11 inch dinner plate. Every photo log returns three things in the response: what reference the model used, the specific estimation it made, and a confidence rating. “Chicken pieces look palm-sized, around 6 to 7 ounces, high confidence with hand visible.” That readout is the difference between “I trust this number” and “I should probably weigh the next one.”
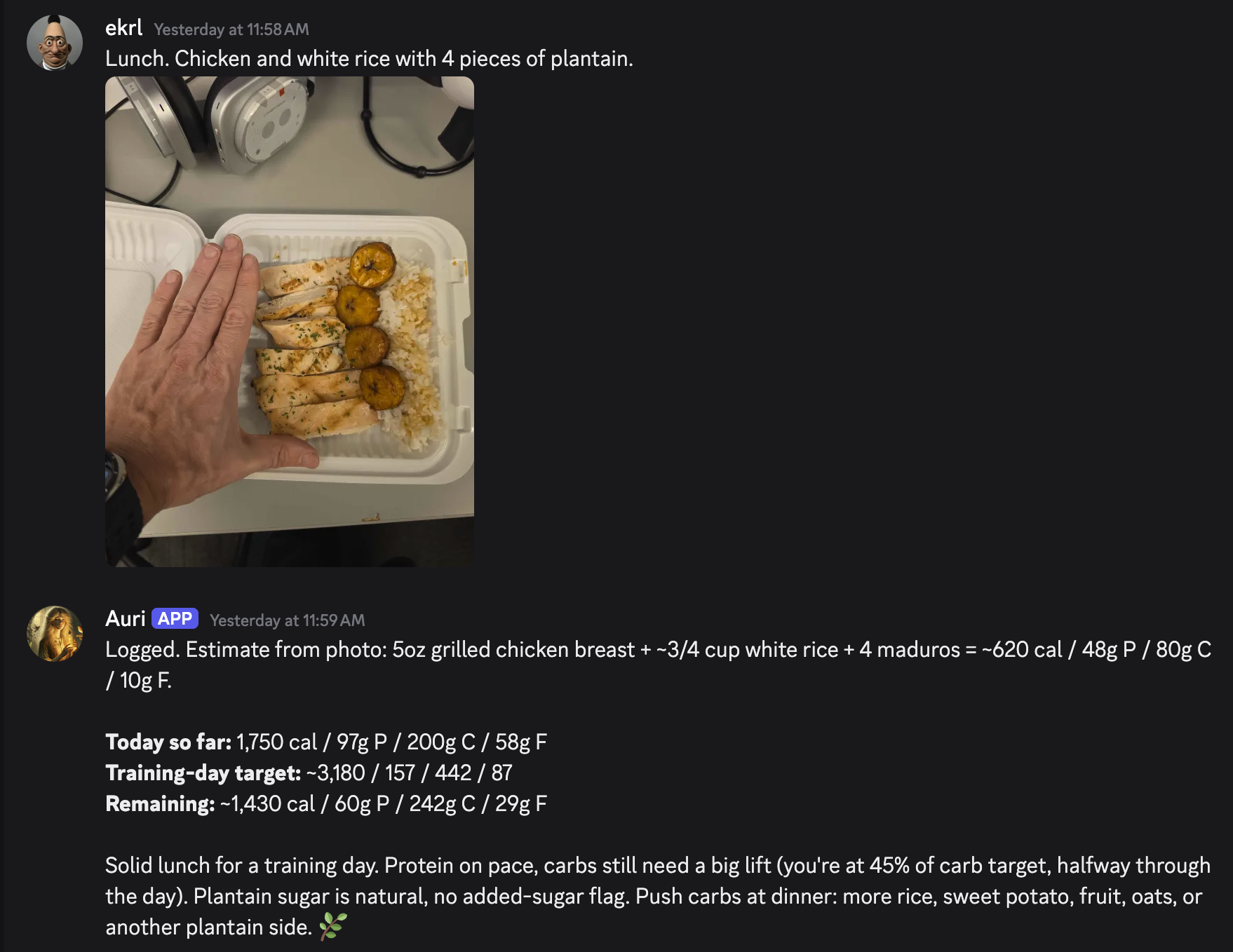
The chicken in that photo got estimated at five ounces because the longest edge mapped roughly to a hand span, the rice volume got bracketed against a fist, and the four maduros landed at about 100 calories each because they read close to thumb-length. That whole estimation chain runs in a single pass against the photo and the description together; if I’d typed “chicken and rice” with no photo, the parser would have asked for a portion, and if I’d sent the photo with no description it would have leaned harder on the visible cues. Together they’re more accurate than either alone.
The training-aware piece
This is the part MyFitnessPal can’t do.
When the system needs to know my targets for a given day, it asks two questions of TrainingPeaks. What was planned, and what actually happened?
Planned training load picks the bucket: a low score is a rest day, a bit higher is an easy ride, higher still is a hard ride, and the top range is a long ride. Each bucket carries its own calorie ceiling, carb floor, and protein target, all calibrated for an older athlete in a calorie deficit (protein lifted to 1.8-2.0 g/kg of body weight because the body builds muscle less efficiently with age, and a fat floor of 1.0 g/kg held non-negotiable because hormones depend on it).
Once a ride is complete and TrainingPeaks reports the actual calories burned, the system updates the day’s targets. It holds protein and fat to the bucket plan (those depend on what the body needs, not how much you burned on the ride), takes the rest-day calorie baseline as the floor for daily living, adds the measured ride burn on top, and lets the carb target absorb the difference. If my plan called for a moderate hard ride and my coach swapped it for a four-hour endurance ride the morning of, my carb target rises to match what I actually did, not what was on the calendar yesterday.
The rest-day rule has a wrinkle worth calling out. A bare rest day defaults to 2,200 calories, but a rest day that immediately follows a hard training day can run up to 2,400 to support refilling the muscle’s fuel stores over a longer window. That’s a post-hard exception, not a standing target, and the system encodes the difference so I’m not eyeballing whether yesterday qualifies.
When the day doesn’t fit the pattern
Real life has shapes that don’t fit “rest day or ride day.” I have scheduled fasts a few times a year that take me off the normal logging cadence. I travel internationally and lose track of meals across time zones. I have social dinners where logging in real time is rude and the calorie count isn’t the point.
The system models all of this as tagged blackout dates: fast, travel, social. On a fast day the breakfast auto-logger doesn’t fire, the dashboard skips the deficit calculation entirely (there’s no meaningful intake number to deficit against), and the meal-reminder scheduler stays quiet. On travel days the intake gets a sane upper bound so a multi-week itinerary with hotel breakfasts and unlogged dinners doesn’t fake out the rolling average. Social days log the meal but don’t moralize about the deviation.
Those rules feel like overhead until you skip them once and watch the dashboard tell you you’re 1,500 calories under target on a day you ate three full meals at someone else’s house.
The dashboard
Daily intake with a projected total based on time of day, deficit per day, rolling weight, training load, and protein-per-meal distribution all on one page. Days are color-coded by classification: in-progress, baseline incomplete, complete, blackout. The piece that actually changes my behavior is the protein-per-meal column. Hitting 160g over three meals at 30, 50, and 80 isn’t the same as hitting 160g at 40, 50, and 70 from a muscle-building perspective, and for an older athlete the dose at each meal matters at least as much as the daily total. The dashboard surfaces the distribution rather than just the total, which is the metric that actually matters.
Built with Chart.js and served from the same Astro site that hosts my cycling dashboard, deployed as a static page on Vercel and regenerated daily.
Advice that knows what you rode
Asking the bot “what should I eat next” doesn’t return a generic answer. The advice prompt is constrained: the model gets the day’s targets, what’s been logged so far, the planned and completed workout, and a hard rule that it returns one specific recommendation in two or three sentences. Nothing about morality. Nothing about what I “should” have done. Just “you’re at 1,490 of a 3,500 cal hard-ride target with 110g of carbs left to put away before tomorrow’s hard session falls flat; a rice-and-chicken bowl gets you most of the way there.”
The prompt that runs the advice model explicitly bans bullet points. Advice is a sentence, not a checklist. The same prompt also bans em-dashes, because em-dashes are how language models give themselves away.
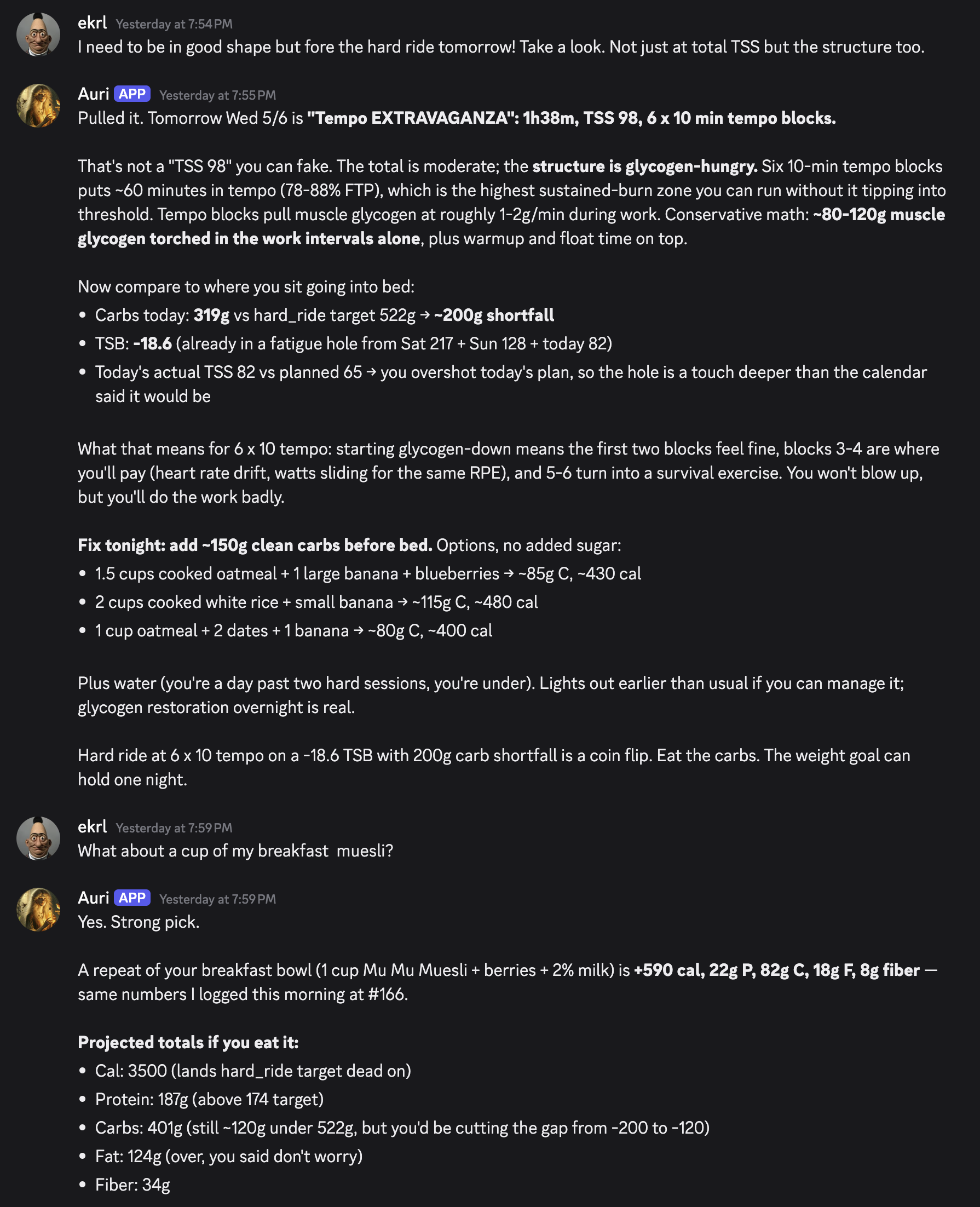
The thing that screenshot is showing isn’t a calorie number; it’s the system reading the structure of tomorrow’s session and reasoning backward from the work blocks to a fuel target, then forward from current intake to a fix that lands the carbs in time to matter. Six rounds of ten minutes at near-threshold effort aren’t something you can fake your way through on a half-empty tank. The advice layer knows that, names it, and tells me to eat 150g of carbs before lights-out instead of advising me generically about “fueling the work.”
Hard restrictions
Two hard restrictions sit underneath the entire stack: no added sugar, and no alcohol in any form. Those aren’t preferences; they’re constraints that the food parser, the advice layer, and the dashboard all enforce. Foods with hidden added sugar get flagged on every log, even when I knowingly chose them. The point isn’t to suppress the choice; it’s to make sure I’m seeing what I’m eating.
What I’d change
Weight logging is manual right now; I’m working on a pipeline to pull it automatically from my phone.
Photo logging works but the failure mode (no hand visible, low light, mixed plates) is “estimate with low confidence” rather than “ask me to retake.” That’s the right default for now (I’d rather have a low-confidence number than nothing) but a short clarification path for the worst photos would be a real improvement.
Each coaching request is independent right now, with no continuity across the day. If I ask at noon and again at 6 PM, the second answer doesn’t know what the first one said. Solvable with a small per-day memory of the conversation. Not built yet.
In closing
It’s a personal tool, in active use, in the middle of a training block I actually care about. It runs on the same server as my cycling dashboard, talks to Postgres, talks to TrainingPeaks, talks to Discord. It’s not a product, and it’s not trying to be one. It’s the thing I built because the apps on the App Store have no idea what TrainingPeaks just told my legs.